

Por: Nicolás López
La caña de azúcar es un cultivo que juega un papel fundamental en la agricultura mundial. A nivel regional, la caña de azúcar es uno de los cultivos insignia del Valle del Cauca desde el punto de vista histórico, económico e incluso cultural. Sin embargo, los datos genómicos disponibles para este cultivo son escasos y difícilmente pueden asociarse a otras fuentes de información, lo que ralentiza su estudio y la comprensión de sus mecanismos moleculares.
En este trabajo, nos centramos en el cultivar S. spontaneum AP85-441 y utilizamos dos secuencias de genomas, identificadas como v2018 y v2019. Se ha desarrollado un algoritmo implementado en Python para integrar la información de expresión génica y de anotaciones funcionales de estas dos versiones del genoma y así estandarizar los identificadores de genes y alelos con una nomenclatura única. Al utilizar la alineación global con BLASTn y un algoritmo de optimización de coincidencias de grafos, se logró maximizar el número de alelos asignados y evitar la duplicación de valores de expresión en el conjunto final de datos. El conjunto de datos resultante proporciona matrices consolidadas de la expresión de alelos y genes para el cultivar APS85-441, que se pueden utilizar para experimentación genómica y exploración adicional en esta variedad de caña de azúcar.
El conjunto de datos consta de información de 96 experimentos con datos de expresión. La matriz de expresión de alelos de v2018 tiene 112,788 transcritos, correspondientes a todos los perfiles de expresión de cuatro alelos por gen. Para esta versión del genoma, se reportan 109,050 genes, lo que sugiere que se consolidan pocos alelos. La matriz de expresión de alelos de v2019 consta de 83,821 transcritos. El conjunto de datos v2019 se consolidó en 35,516 genes, con solo una discrepancia de seis genes en comparación con los datos previamente reportados en la literatura.
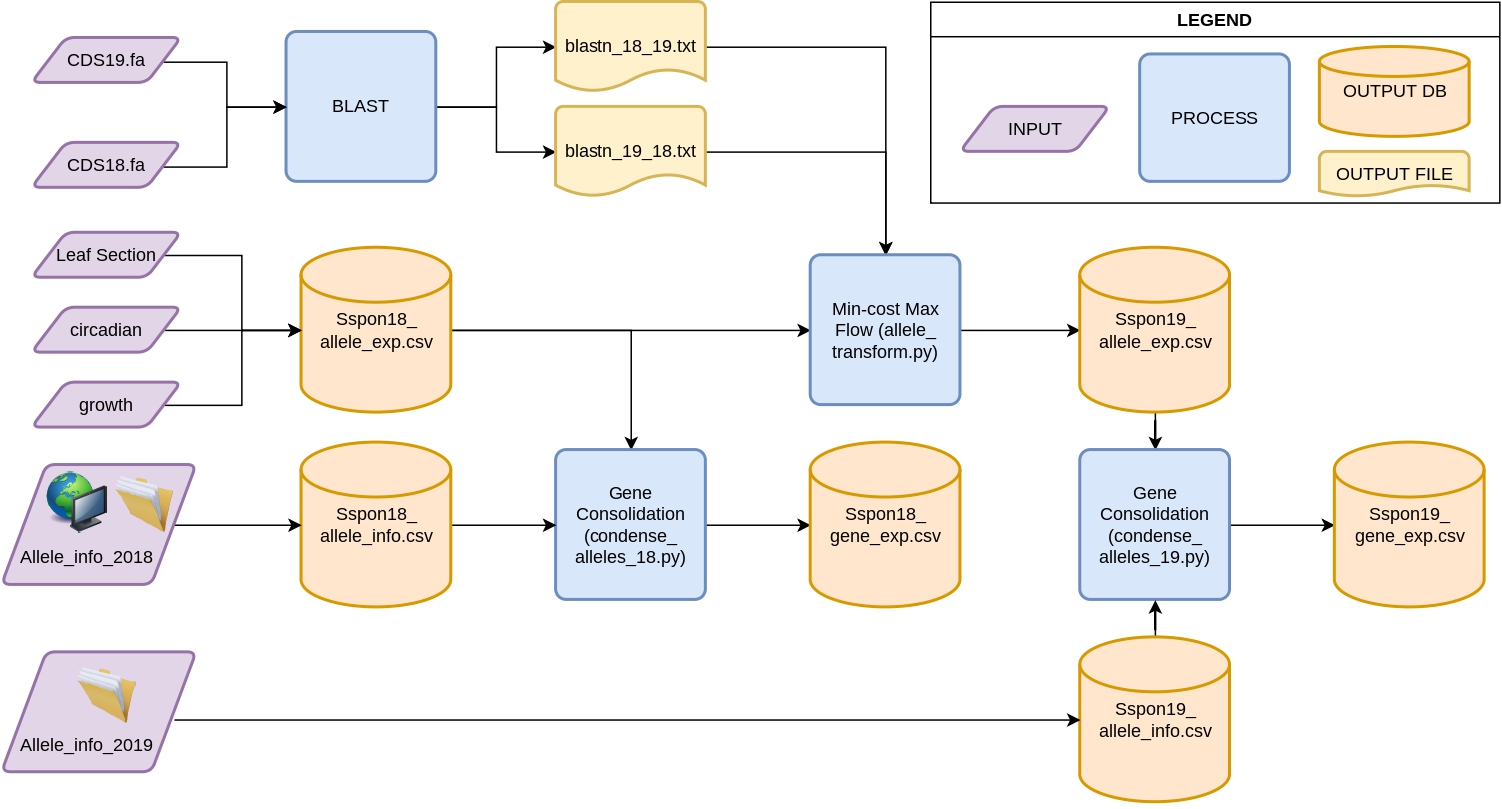
- La figura muestra el flujo de información y el procesamiento realizado a estos datos (en azul). Utilizando diversas fuentes de información (en morado), se usó software especializado (BLAST) o algoritmos propios para la consolidación y el mapeo de la información de expresión desde el nivel de alelos al nivel de genes (en amarillo).
El estudio tiene posibles implicaciones en la comprensión de los mecanismos de mejoramiento selectivo (heterosis) en los cultivos híbridos modernos, como los utilizados para producir azúcar y etanol. De esta forma, se puede mejorar el rendimiento y la sostenibilidad de la caña de azúcar, no solo a nivel regional sino también global.
El trabajo futuro en este sentido apunta hacia la utilización de estos datos en la generación de redes de co-expresión que permitan un enriquecimiento funcional de la caña de azúcar. Si bien la predicción de anotaciones es un problema bien explorado y permite encontrar potenciales anotaciones, la validez de las mismas debe mirarse detenidamente.
Conozca más sobre este tema en el siguiente artículo: Gene Expression Datasets for Two Versions of the Saccharum spontaneum AP85-441 Genome









