

Autores: Nicolás López-Rozo; Mauricio Ramírez-Castrillón; Miguel Romero; Jorge Finke y Camilo Rocha
La caña de azúcar es una especie de pasto alto con alta biomasa y producción de sacarosa, y el cultivo más grande del mundo por cantidad de producción. Su adaptación al entorno evolutivo y la respuesta de reproducción antropogénica han dado como resultado un genoma autopoliploide complejo.
Se han informado pocos esfuerzos en la literatura para documentar la coexpresión y anotación de genes de este organismo y, cuando están disponibles, utilizan diferentes identificadores de genes que no se pueden asociar fácilmente entre estudios. Este documento descriptor de datos presenta un conjunto de datos que consolida matrices de expresión de dos versiones del genoma de Saccharum spontaneum AP85-441 y un algoritmo implementado en Python para obtener mecánicamente este conjunto de datos.
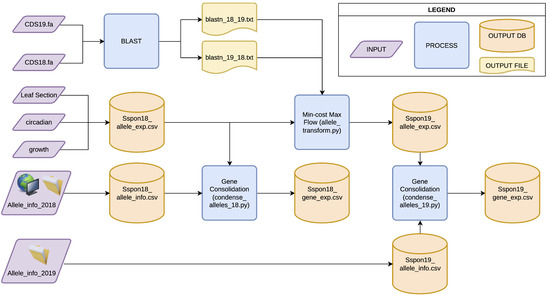
Los datos se procesan a partir de la información a nivel de alelo de las dos fuentes, con BLASTn utilizado bidireccionalmente para sugerir mapeos factibles entre los dos conjuntos de alelos y un algoritmo de optimización de coincidencia de gráficos para maximizar la identidad global y la singularidad de los genes. Las tablas de asociación se utilizan para consolidar los valores de expresión de los alelos a los genes. Las matrices de expresión aportadas comprenden 96 experimentos y 109.050 y 35.516 de las dos versiones del genoma. Pueden representar una reducción significativa de costos computacionales para futuras investigaciones sobre, por ejemplo, la generación de redes de coexpresión de caña de azúcar, la predicción de anotaciones funcionales y la identificación de genes específicos del estrés.
Conozca este artículo completo en nuestra sección de: Generación de Nuevo Conocimiento









